 |
 |
 |
 |
 |
 |
 |
 |
Speaker Recognition Technology
This page describes speaker recognition technology in some detail and from different viewpoints. Here is a short description of the speaker modeling and its relation to phonetics, then some computational techniques to solve the speaker recognition task, and finally some info on the automatic recogniser implementations in the PUMS project.
Human Speech Organs
The human speech is, technically speaking, air pressure variations caused by movements of muscles and other tissue within the speaker. The speech organ system is a complicated mechanism but in short one can say that the lungs pump air through the windpipe to the surrounding environment via mouth and nose and speech sounds are formed during this process. The brain drives the muscle system that controls the lungs and vocal cords, the shape and volume of the windpipe, size and shape of the oral cavity, nasal passage controlling airflow through the nose, and finally, the lips.
Parts of the physical system producing speech vary from one person to another. These variations have a direct consequence that each person produces speech signal characteristic to him. This means that the effect of message content, acoustic environment, etc. in the speech signal is ignored. In automatic speaker recognition the target is to develop a system that is able to discriminate speakers based on these personal characteristics by processing speech audio waveforms recorded from the different speakers. Moreover, automatic discrimination should not depend or the linguistic content of the speech samples.
The University of Helsinki Student Library has Internet material about human speech organs in Finnish. In a "Basic Phonetics Dictionary" there is a diagram of the speech organs in chapter 6: "Speech Organs". One of the authors, professor Antti Iivonen is from the Department of Phonetics in University of Helsinki and he is related to the PUMS project.
John Coleman, who is the Director of the Oxford University Phonetics Laboratory, has a collection of phonetics links, and a short page discribing the most important human speech organs titled "the Vocal Tract and Larynx".
Automatic Speaker Recognition from Speech Audio
The speech is a natural communication mechanism between two persons but it is very complex from automatic analysis viewpoint. The message is encoded in air pressure variation. The speech audio signal is roughly defined as the air pressure in a listeners location. The signal can be though of arising from the speaker articulating the message that he wants to express. Besides the message and the effect of speech organs we may think that there are other things effecting too, as in the coarse description in the main page. The audio signal is sampled and quantized. This digital speech signal is the input of speaker profile management and automatic speaker recognition systems. The figure below illustrates the coarse structure of such a system.
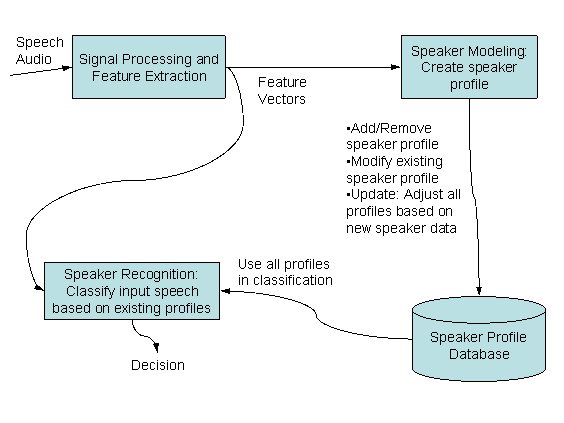
Signal Processing and Feature Extraction
The information rate in digital or analog speech signal is huge. In automatic recognition systems it is very common to base the speech analysis in the local spectrum of the speech signal. Short overlapping intervals from the digital speech signal are extracted. This is called signal framing. The spectra of the frames are computed, usually followed by dimensionality reduction, for example, with help of filter bank analysis. During this process the dimensionality of the local spectra is typically dropped to 1-5 % of the original amount of data in a local spectrum. The choice of filter bank can be crucial to the recognition result quality. It is possible to also construct filter bank that has optimal speaker discrimination properties when used with a classifier. The filter bank output is usually processed further to improve classifiers made with standard construction, for example, VQ or GMM classifiers. There are few reasons why the dimensionality needs to be dropped, most important one is to make the classification problem well-posed and other obvious reason is reduced computational cost.
Constructing Speaker Profile Database for Clustering
When the signal processing methods, e.g. filter banks and such, are chosen well, the speaker characteristics are captured efficiently in feature vector set produced from speech frames. For the speaker recognition classification purpose it is sufficient to store information about the probability distribution of the feature vectors in the database in some accuracy. Typically the feature vectors are clustered and a codebook is stored for the purpose of nearest neighbour classification, i.e. cluster centroids are stored. Feature vector computation reduces the amount of data streaming from the audio channel but the clustering compresses the data even more, but still manages to capture the essential speaker characteristics in speaker profiles. As a side product of such data reduction we get very efficient computation and real-time recognition in most applications.
Speaker Recognition: Profile Matching
During the speaker recognition a stream of audio samples is input to the program. Before that, the speaker database must be read and comparable feature vectors must be computed from the input audio signal. The feature vectors are then matched to the contents of the database.
In University of Joensuu we try to improve both the recognition accuracy and the efficiency of the computations during recognition. An example of recognition accuracy improvement technique is a committee classification, where common time domain and spectral measurements are used together in classification to provide more accurate recognition. Several techniques for speeding up computations are also investigated, like different speaker pruning techniques to avoid comparing input speech samples to all of the speaker database, as well as using compressed input data to the classification.
Programming Languages and Platforms
The final implementation for the algorithms is done in ANSI C mainly for its portability. The user interfaces are done with C, C++, or Delphi, depending on the target platform. For example, the applications working in Series 60 mobile devices will be a mixture of C and C++: the computational routines can be mostly C implementations but the Series 60 user interface framework design is object orient and the implementation is in C++ language. Prototypes and software development is done in the PC environment. Research of new speaker recognition and classification techniques is often done with the Matlab software, espacially when it is not worthwhile writing complicated highly experimental algorithms in C.
One of the main target of the whole project is to produce a speaker recognition application that works well in Nokia mobile phone with Series 60. The Series 60 platform is an open application framework built on top of Symbian operating system. The Symbian is used at least in the Nokia mobile phones 7650, 3650, N-Gage, and 6600. To be more specific,
- the Nokia models 7650, 3650, and N-Gage have Symbian OS 6.1 with Series 60, whereas
- the model 6600 has Series 60 v2 with Symbian 7.0s.
Information on other phones with the Symbian OS can be found, for example, in www.nokian-gage.com.