
![]() Front Page
Front Page
RESEARCH TOPICS
![]() Automatic and Semi-automatic Essay Grading
Automatic and Semi-automatic Essay Grading
![]() Evaluation of the Natural Language Parsers
Evaluation of the Natural Language Parsers
![]() Plagiarism Detection in Software Projects
Plagiarism Detection in Software Projects
![]() Visualization of the Social Interaction in Virtual Environments
Visualization of the Social Interaction in Virtual Environments
WHO & WHAT
![]() People & Alumni
People & Alumni
![]() Publications
Publications
LINKS
![]() Educational Technology @ Department of Computer Science
Educational Technology @ Department of Computer Science
![]() Department of Computer Science in University of Joensuu
Department of Computer Science in University of Joensuu
FUNDERS
![]() National Technology Agency of Finland (TEKES)
National Technology Agency of Finland (TEKES)
![]() European Commission - Research Directorate
European Commission - Research Directorate
![]() Discendum
Discendum
![]() Karjalainen
Karjalainen
![]() Lingsoft
Lingsoft
![]() Tikka Communications
Tikka Communications
![]() Intranet (password required)
Intranet (password required)

This title basically means specifying the problem of plagiarism detection, development of necessary software tools, solving related algorithmic issues and thorough evaluation. Although this research at the first sight seems to be quite narrow, technical and even skin-deep, in practice it requires serious work in different areas, including pedagogy, software engineering, proper evaluation techniques development and algorithmic analysis. Moreover, some algorithms, initially designed for plagiarism detection, can be used in other problems, which are, strictly speaking, not related to plagiarism at all, such as collaboration analysis, specific tasks of information retrieval, etc.
This research springs from a software plagiarism detection project, which is maintained at our department quite seriously for the last several months. The initial task definition was simple: suppose a teacher received a couple of students' laboratory works (which are computer programs, e.g. in Java or C++), and now he/she wants to check them for "borrowings" or pieces of "collective work". In this situation, very usual in pedagogy practice, a teacher may need a tool, which tries to perform this job automatically. Such tool can, for example, print pairs of suspiciously similar documents from a given collection.
Although, for now we are still working on such "teacher's tool", it is clear that it can be used (with reasonable modifications) for other non-related tasks.
Suppose a teacher receives a couple of students' submissions and wants to check them for plagiarism instances. Suppose also that we already have a routine (possibly brilliant), which somehow compares two works and prints a report about found plagiarisms. Unfortunately, a major problem still remains. If you want to check two works, you have only one pair; five works give you ten pairs and so on. The number of pairs to be checked grows quadratically. If you have twenty students, it is OK; it is satisfiable also if you have 50 or even 100 students, but what if you are dealing with a big university or distant educational centre? You also may be interested in comparison of a given file against some large existing document collection (e.g. "Open Internet Bank of Students' Laboratory Works").
This problem seems to be the most challenging: to develop an algorithm, which allows us to check many works in a reasonable time. For now we already have a working version, but it definitely can be improved (as anything else in this world). The basic idea of the algorithm is to test a file against the whole collection at once, so we can get rid of this pairwise comparison.
The most difficult point in this algorithm is to find a good tradeoff between speed and detection performance. Obviously, it is impossible to have a linear time algorithm, which is as good in detecting as quadratic time one, but it many cases its disadvantages and problems can be reduced to a minimum. Here we really have an open field for our fantasy. For example, we can try to develop a hybrid algorithm, which rapidly finds suspicious documents, and after that applies a highly reliable (yet slow) routine to these selected works.
Here we should state the difference between the typical task of any Internet searching engine (which also can rapidly browse many documents to find the ones matching your query) and plagiarism detection. In case of searching engine it is generally assumed that the query contains only several words (so there is a space for an optimization); in our case "query" has roughly the same size as typical document in the collection. Furthermore, plagiarism detection cannot be reduced just to the process of single words searching.
Let's now summarize directions of our work:
- To define the concept of plagiarism (as applied to software plagiarism mostly) and to formulate, how plagiarism instances can be extracted by a computer.
- To develop specific techniques, suitable for software plagiarism detection.
- To design a rapid (linear time complexity) and efficient algorithm for detecting plagiarism instances. This algorithm should be able to test all files in a collection against each other, and also test some given file against a "document bank".
- To perform a reliable, thorough evaluation of the performance; to collect a bank of real students' works and teacher opinions about possible "borrowings".
- To implement a tool, suitable for everyday usage in reality, by real teachers in real schools and universities. This means development of a reliable algorithm and a rich, user-friendly interface.
- To apply developed techniques to other problems, not related to plagiarism detection.
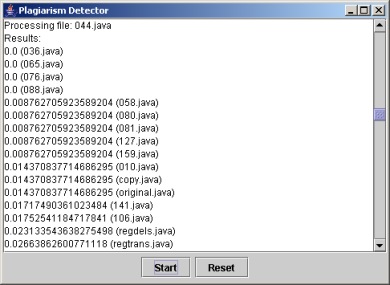
Figure 1: A Plain Text Results
Now we are mainly concentrated on fast algorithm development. The basic ideas of the current solution are described in the draft of our paper. Another issues concern user interface. For now our program allows to see plain text results (Fig. 1) and so-called matches graph (Fig. 2).
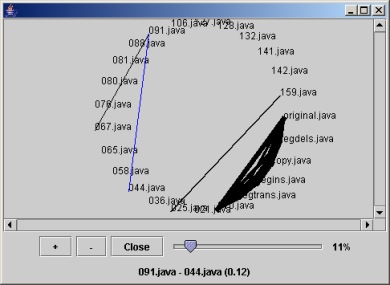
Figure 2: A Matches Graph
Research Assistant Maxim Mozgovoy, mmozgo@cs.joensuu.fi