Bayes Decision Theory
Bayes Decision Theory Hierarchical Clustering
Hierarchical ClusteringAGGLOMERATIVE ALGORITHMS
Agglomerative algorithms start with initial clustering R0, in which each data vector forms a cluster. Thus, for the data with N data vectors, N clusters are formed. Let g(Ci,Cj) be the proximity function, which is defined for all possible pairs of clusters The general agglomerative scheme is stated as follows:
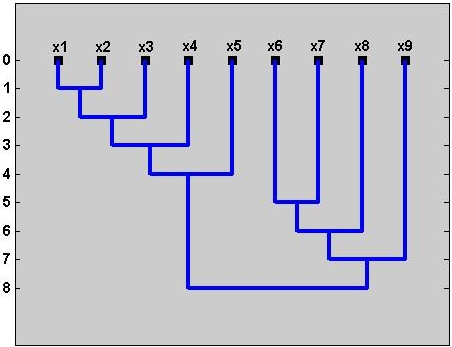
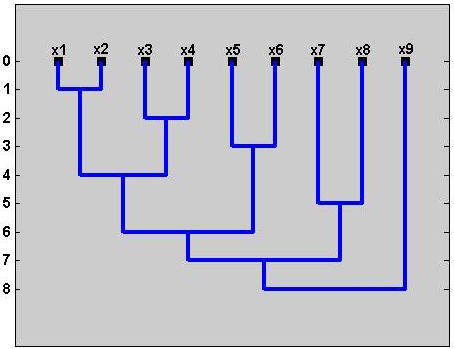
The sequence of clustering procuded by an agglomerative algorithm is often
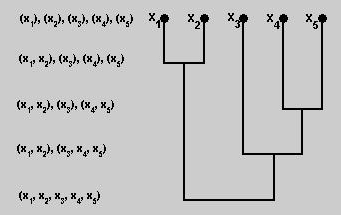
represented by a dendrogram. An example of the clustering hieracrarchy and its corresponding dendrogram
are shown in the figure below.
DIVISIVE ALGORITHMS
Compared to agglomerative clustering, the divisive clustering follow the inverse path. The initial clustering R0 consists of one cluster which includes all the N data vectors. At each iteration step the number of clusters is increased by one and in the final clustering there are N clusters, with one data vector in each cluster. Th general divisive scheme s stated as follows.
The main drawback of the divisive clustering is its hugecomputational complexity. Some computational simplifications must be done if divisive scheme is used in practical applications.
THE NUMBER OF CLUSTERS
The lifetime of a cluster is defined as a difference between the proximity level at which the cluster was created and the proximity level at which the cluster was combined with any other cluster. The dendrograms indicating the presence of one major cluster (the upper one) and two major clusters (the lower one) are shown below.