Further notes on lecture 3
Fuzzy systems
For further information, you can check a
a good tutorial.
Traditionally, fuzzy rules are defined by a human expert. However,
nowadays it is possible to learn them from data, too (at least in some
extent). The approaches use either neural networks (they furst learn
''fuzzy neural networks and then read the fuzzy rules from the
network) or genetic algorithms. Here is one example:
Roubous et al.: Learning fuzzy classification rules from data
Dempster-Shafer theory
The most flexible feature in D-S theory is that we can represent
ignorance. For example, if the beliefs in A and not A are m(A) and
m(-A), then it is possible that m(A)+m(-A)<1 and the amount of
ignorance is 1-m(A)-m(-A).
We can demonstrate grafically, how beliefs m1 and m2 are combined in
Demspter-Shafer rule:
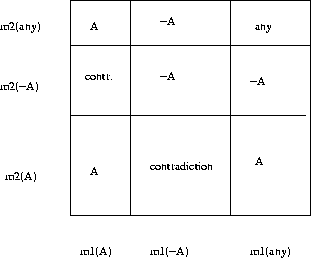
The area of squares describe the combined belief in A, not A or
ignorance (any). We have to normalize the beliefs by dividing with the
area of consistent (non-contradictory) beliefs. The whole square
corresponds belief value 1.0. The contradictory area has value
m1(A)*m2(-A)+m1(-A)*m2(A). Thus the remaining area is
K=1-m1(A)*m2(-A)+m1(-A)*m2(A). Now the combined beliefs are:
m1+m2(A)=m1(A)*m2(A)+m1(any)*m2(A)+m1(A)*m2(any)/K
m1+m2(-A)=m1(-A)*m2(-A)+m1(any)*m2(-A)+m1(-A)*m2(any)/K
And the mount if ignorance is:
m1+m2(any)=m1(any)*m2(any)/K.
Notice that A can be also a set of propositions, e.g. A=A1 or A2.
Decision trees
More links to
material
We discussed, whether decision trees are robust i.e. how sensitive
they are to small changes in the training data. This depends on
several factors, especially, how we select the original training
set. Removing some of contradictory rows can produce serious
errors. For example, if 50 rows contain values A,B,C and 49 rows
values A,B,-C, we will remove all the latter ones and conclude C from
A and B. However, conclusion -C is nearly as plausible. A small change
in data set, just two more rows containing values A,B,-C would produce
different results. Another scheme for solving contradictions could
work better, but still the restriction of demanding dicriminatory
classification (every data point can belong to only one class) remains.